
你是否已经听说了最近市场上发布了几款新的 CPU?它们的性能非常强大!当然,我说的就是 ARM Cortex-A75 和Cortex-A55,即首批基于新近发布的DynamIQ 技术的Cortex-A系列处理器。本文我们讨论的就是 Cortex-A55:一款对为未来数字世界举足轻重的处理器,原因如下。
出生名门,久经考验

想要理解 Cortex-A55 的真正潜力,我们来简要回顾一下其上一代产品:ARM Cortex-A53。采用这款 CPU 的设备已超过 15亿台,该 CPU 依然是当今业界出货量最高的 64 位 Cortex-A 系列 CPU。Cortex-A53 于 2012 年发布,其独一无二的设计,集性能、低功耗以及尺寸扩展性于一身,具备一系列多用途特性,因而可应用于诸多市场,其中包括高端智能手机、网络基础设施、汽车信息娱乐、高级驾驶员辅助系统 (ADAS)、数字电视、入门级移动设备和消费级设备乃至人造卫星。
然而自 2012 年以来,我们周围的世界发生了许多变化。我们现在看到的新兴趋势表明,保持互联、万物智能的数字世界具有非常大的发展潜力。从完全自主的自动驾驶汽车到各类设备上的智能应用程序,人工智能 (AI) 和机器学习 (ML) 将真正融入到我们的日常生活中,这一点已成定局。物联网 (IoT) 应用的盛行意味着“物”的爆炸性增长,越来越多的“物”在持续生成数据、消费数据以及与数据进行交互。增强现实、虚拟现实以及混合现实 (AR、VR 以及 MR) 注定会彻底改变我们人类之间以及人机之间的互动方式,将现实世界与数字世界融于一体。
在过去两年里,ARM 的工程师致力于研究 Cortex-A53 的后继产品,以满足这类新兴技术的需求,我们的目标是打造出一款性能、效能以及扩展性均大幅提升的 CPU,而且这款 CPU 还需要具备诸多先进的特性,从而满足从端到云的各种未来应用需求,幸运的是我们做到了。
性能全面提升
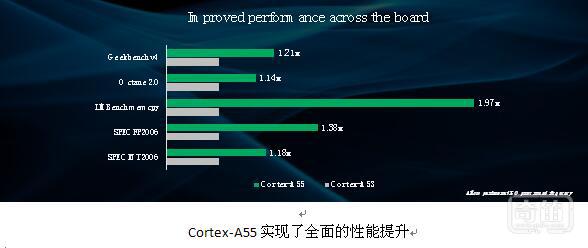 Cortex-A55 采用最新的 ARMv8.2 架构,并在其前代产品的基础上打造而成。它在性能方面突破了极限,同时依旧保持了与 Cortex-A53 相同的功耗水平。我们尽全力改进 Cortex-A53,并赋予其以下特性:
Cortex-A55 采用最新的 ARMv8.2 架构,并在其前代产品的基础上打造而成。它在性能方面突破了极限,同时依旧保持了与 Cortex-A53 相同的功耗水平。我们尽全力改进 Cortex-A53,并赋予其以下特性:
• 在相同的频率与工艺条件下,内存性能最高可达 Cortex-A53 的两倍
• 在相同的频率与工艺条件下,效能比 Cortex-A53 高 15%
• 扩展性比 Cortex-A53 高十倍以上
这些归功于我们专注于 Cortex-A53 现有的设计理念并挑战这些理念。
• 我们对分支预测程序(branch predictor)进行了全面修改,在其算法中融入了神经网络元素来改进预测。此外还新增了零周期分支预测程序(Zero-cycle branch predictor)以便进一步减少流水线中的泡沫。这样可以使指令之间的空闲时间越来越短。
• 我们的设计是,使二级高速缓存对每一颗 CPU 而言都是专用缓存,这样一来与 Cortex-A53 相比,二级高速缓存的存取时间缩短了 50% 以上。我们还将二级高速缓存的工作频率设计成与 CPU 相同的频率。通过降低延迟大幅提升 CPU 在各类基准测试工具中的性能。
• 我们推出了三级高速缓存,可供集群内的所有 Cortex-A55 CPU 共享。这让 DynamIQ 集群能够得益于 CPU 附近增多的内存容量,从而提升性能、降低系统功率。三级高速缓存是 DynamIQ 共享单元 (DSU) 的一部分,DSU 是DynamIQ 处理器中的一个新的功能单元。
• 8 位整数矩阵乘法对神经网络性能的影响超过85%。Cortex-A55 NEON流水线中增添了新的架构指令,使其能够在每个周期执行 16 次 8 位整数运算。这些新的指令还使该 CPU 能够在每个周期执行 8 次 16 位浮点运算、对两条 MAC 指令进行舍入操作,有利于色彩空间转换。
相较Cortex-A53,实现效能的大幅提升
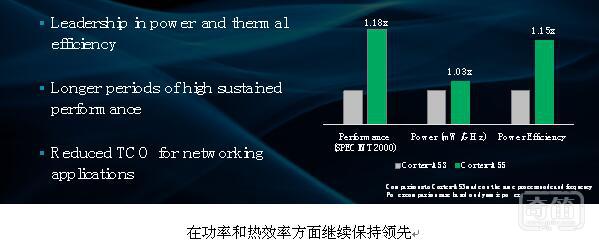
对分支预测程序、NEON 和 FP 单元的上述改进以及内存延迟的缩短仅仅是 Cortex-A55 取得大幅性能提升的部分原因。Cortex-A55 不但实现了大幅性能提升,而且保持了与 Cortex-A53 相类似的功耗。总而言之,Cortex-A55 在节能性方面实现了 15% 的提升。相对于性能而言,功率在产品设计中更加重要。在提供同等性能的情况下,Cortex-A55 消耗的功率比 Cortex-A53 低 30% 之多!
Cortex-A55提供持续性能的时间远比当今的 Cortex-A53 解决方案更长。这一点对于 AR、VR 以及 MR 等领域的用户体验而言至关重要,这些领域预计将会在未来移动市场上占据主导地位。这些使用场合已经高度线程化,对延迟有严格的要求。后者指的是移动时间延迟,根据行业研究,这种延迟需要保持在 20 毫秒或以下,这样才不会导致恶心和头晕。虽然当今的 CPU 已经实现了达到 20 毫秒延迟所需的性能水平,但是发热限制意味着这些 CPU 无法长时间维持这样的性能水平。有了 Cortex-A55,我们就能给出未来 VR 设备中延长持续性能时间的解决方案。

行业领先的效率让 Cortex-A55 在基础设施市场卓尔不群。以太网供电 (PoE) 无线接入点以及安装在后视镜上的发热受限的汽车解决方案等应用均可利用热效率极高的 Cortex-A55 在特定的发热范围内提供最高性能。在 5G 远程无线电头端 (RRH),Cortex-A55 CPU 还能够在特定功率范围内最大限度增加网络吞吐量。
从端扩展至云

除了性能与效率以外,Cortex-A55 的物理芯片尺寸以及计算性能也具有极高的扩展性。为此,它包含了多个 RTL 配置选项,从而使可配置容量达到了 Cortex-A53 的十倍。事实上,它拥有 3,000 多种独特的配置,因而成为了史上最具扩展性的Cortex-A CPU。
Cortex-A55 延续了 Cortex-A53 的灵活性,具备 NEON、Crypto 以及 ECC (纠错码) 等选项,但是也采用了新的实用配置选项。例如,专用二级高速缓存的可配置容量从 64KB 到 256KB 不等,可带来 10% 的性能提升。专用二级高速缓存能够很好地提升性能,而且它无疑会成为诸多市场的默认之选,它还被设计成了可选项,以便在物联网等对尺寸敏感的市场上进一步减小芯片尺寸。
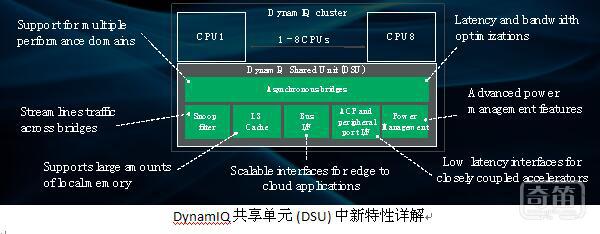
DSU 无论在 Cortex-A55 还是在 Cortex-A75 上都很常见。它包含更多的配置选项,可根据用户自身的应用情况进行定制。例如 CPU 之间共享的三级高速缓存可从 0KB 扩展至最大 4MB。它还通过 AMBA 5 ACE 或 CHI 支持多用途接口选项,从而可用于更广泛的系统。加速器相干性端口 (ACP) 和低延迟外围端口 (PP) 也被集成到 DSU 当中,这让紧密耦合的加速器能够连接至 Cortex-A55 以便处理通用计算。这些特性加上 Cortex-A55 的机器学习功能,让更多的计算能够在更靠近物联网网关应用“端”的地方执行。
囊括诸多先进特性,可用于各类新兴应用

人工智能会越来越普及,这已不是什么新鲜事。引申开来,我们的设备运行机器学习任务也会变得十分普遍。有多种方法可以在芯片上实现机器学习的处理,然而 CPU 在这方面拥有独特的优势。CPU 可进行通用计算,因此它可以运行到人工智能应用的芯片当中。目前机器学习和人工智能持续换代,固定功能的硬件不但价格昂贵,而且对机器学习而言容易过时。
对 Cortex-A55 NEON流水线的改进和新增的机器学习指令意味着 Cortex-A55 在矩阵乘法运算方面的机器学习性能比Cortex A53要高出很多。最近发布的ARM 计算库(ARM Compute Libraries)是专为 ARM Cortex-A NEON 和Mali GPU IP而优化的入门级软件函数集,它也可以应用于 Cortex-A55 NEON 并进一步提升其机器学习性能!

Cortex-A55的可靠性、可用性和可服务性 (RAS) 特性也很高,这些特性使其能够服务于基础设施以及汽车等各个领域。对汽车市场而言,Cortex-A55 的安全性现已得到提升。它在每一级高速缓存上均提供可选的 ECC 和奇偶校验特性,而且还支持“data poisoning”,这种方法可推迟已检测到的、不可纠正的错误,适用于更有弹性的系统。它还是首款在避免系统故障方面采用全新设计流程的 Cortex-A 系列 CPU,因而在搭配Cortex-R52的情况下十分适合 ASIL D 应用。
深度嵌入高级电源管理特性
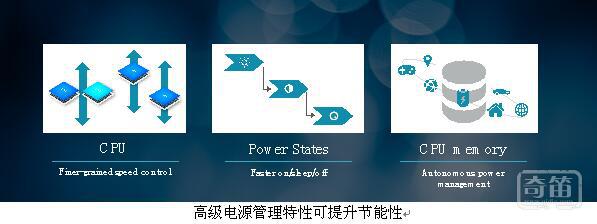
Cortex-A55具备诸多全新的电源特性,例如硬件控制状态转换能够更快地从 ON 转换至 OFF。Cortex-A55 还能够根据当前运行的应用程序自主地关闭三级高速缓存。对于 VR 等需要更多内存的重载型应用程序,三级高速缓存会完全打开。然而对于音乐播放等完全驻留在一级和二级高速缓存中的轻载型应用程序而言,三级高速缓存会被关闭。额外还有两种功率模式用于重载和轻载之间的应用情形。
现在还可以创建单颗 CPU 或 CPU 群组,其中每一颗 CPU 都处于集群内各自独立的电压域中,因此能够更精细地动态提升电压和频率。这有两大好处:首先,它让设计师能够进一步调节系统,从而实现最佳的性能和节能性。其次,这还意味着 DynamIQ 系统能够更轻松地紧密匹配设备多变的发热限制,因此可以最大限度发挥性能。
big.LITTLE处理的新时代
big.LITTLE 技术自 2011 年问世以来一直是异构处理的代名词。因此当今市面上每三台安卓 ARMv8 设备中就有两台依赖 big.LITTLE 技术来实现功率和性能优化。DynamIQ big.LITTLE是 DynamIQ 系统的新一代异构计算技术。
它让设计师能够利用 Cortex-A75 “大” CPU 和 Cortex-A55 “小” CPU 打造出充分集成的解决方案,大小 CPU 在物理上位于单一 CPU 集群中。所有的软件线程迁移和由此造成的大小 CPU 之间的高速缓存窥探(cache snoop)现在均发生在该集群内。与 Cortex-A73 相比,Cortex-A75 CPU 可以用于频率更高的使用场合,同时利用Cortex-A55 依旧保持持续的 DVFS 曲线。这是 big.LITTLE 系统的一项重要设计要求。这些特性合在一起,与上一代 big.LITTLE 技术相比,可大幅提升峰值性能、持续性能以及智能功能。
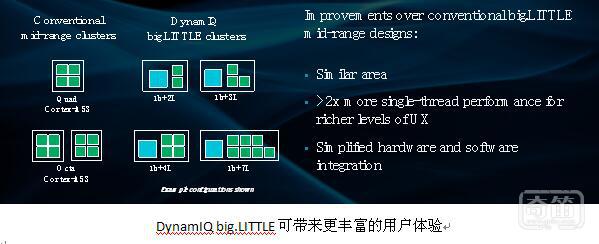 当今的中端移动和消费级市场普遍采用基于Cortex-A53的 4 核和 8 核解决方案。然而,随着人工智能和虚拟现实等高级使用场合从高端市场渗透到中端市场,厂商需要以更低的成本提供更高的性能和智能功能。DynamIQ big.LITTLE 通过推出新的异构 CPU 配置来满足这一需求,例如 1 颗 Cortex-A75 + 3 颗 Cortex-A55 (1大+3小) 和 1 颗 Cortex-A75 + 7 颗 Cortex-A55 (1大+7小) 等等。这些新的配置以类似的芯片尺寸可分别与 4 核和 8 核的 Cortex-A55 设计相比,可以实现 2 倍以上的单线程性能。
当今的中端移动和消费级市场普遍采用基于Cortex-A53的 4 核和 8 核解决方案。然而,随着人工智能和虚拟现实等高级使用场合从高端市场渗透到中端市场,厂商需要以更低的成本提供更高的性能和智能功能。DynamIQ big.LITTLE 通过推出新的异构 CPU 配置来满足这一需求,例如 1 颗 Cortex-A75 + 3 颗 Cortex-A55 (1大+3小) 和 1 颗 Cortex-A75 + 7 颗 Cortex-A55 (1大+7小) 等等。这些新的配置以类似的芯片尺寸可分别与 4 核和 8 核的 Cortex-A55 设计相比,可以实现 2 倍以上的单线程性能。
现已推出基础设施和移动片上系统 (SoC) 设计指南
ARM 长期以来一直在范例 SoC 设计验证我们的知识产权方面有着大量投入。由于 ARM 的知识产权组合与日俱增,这些范例系统的复杂度和范围也随之增长。从 SoC 架构到详细的产前分析,这项工作涵盖了方方面面。ARM 将以“系统指南”的形式提供这类知识。
除了全新 CPU 以外,ARM 还提供各种新的系统指南,这些指南涵盖了移动系统和基础设施系统:
• 针对移动系统的 CoreLink SGM-775 系统指南专为 Cortex-A75、Cortex-A55 以及 Mali-G72 而设计和优化
• SGM-775 包括文档、模型和软件,而且可供 ARM 合作伙伴免费使用
如需详细了解如何实施移动和基础设施系统,敬请访问我们的系统指南页面。
基于 Cortex-A55 的设备预计什么时候上市?
Cortex-A55的最终发布令人激动不已。Cortex-A55 在性能、节能性以及扩展性等方面的长足进步将使其成为 ARM 的下一款出货量最大的 Cortex-A 系列 CPU。然而,激动人心之处不止于此。这一生态系统内的大量 ARM 合作伙伴现已获得 Cortex-A55 的相关许可,我已经等不及想要看一看他们在接下来的几个月里将会发布哪些新一轮智能计算解决方案。虽然我们无法预测基于 Cortex-A55 的设备会以何种形式展现,但是可以确定的是,从2018年起未来将会无比激动人心!















